原题和分析hrbust 的 ACMbook
一道例题
题目太难读了,“The songs will be recorded on the set of disks in the order of the dates they were written.”这句话简直没法理解
但是仔细想想的话,大概就是说把 songs 选一些出来然后切段~~
一道例题
题目太难读了,“The songs will be recorded on the set of disks in the order of the dates they were written.”这句话简直没法理解
但是仔细想想的话,大概就是说把 songs 选一些出来然后切段~~
搞了hexo以后,因为hexo的post文件要用markdown写嘛,然后就来了解markdown了~~~
随便找了点[资料](http://www.aaronsw.com/),一个[点击量很高的github页面](https://github.com/younghz/Markdown)对创始人的介绍:它由Aaron Swartz和John Gruber共同设计,Aaron Swartz就是那位于去年(2013年1月11日)自杀,有着开挂一般人生经历的程序员。维基百科对他的介绍是:软件工程师、作家、政治组织者、互联网活动家、维基百科人。
果然是开挂般的人生啊然后被封号了,想到我自己,恐怕,这些都只能放进幻想里面了吧。
chinafinal结束以后第一件事情搞了个blog,然后接下来就是,每次的题目除了AC以外把WA的原因都总结一下吧。。。
自己电脑上码题目一直是visualstudio,最不爽的地方就是这个工程啊,一建就是一大串文件和一个很复杂的目录,尝试换过很多IDE,然而还是离不开VS天神级的调试。VS上debug实在是太容易。
虽然好像从来没有重新看过自己写的题,但是把写过的题目存档还是很有成就感的事情,为此在github上加了一个Repo来存题目,然后每天回寝室的时候用批处理把一天新写的代码全部上传,然后清空Code文件夹……感觉这样清楚很多,不会以前那样一堆题目的cpp放在文件夹里,还有各种编译器生成的.exe .o文件乱乱的。
ChinaFinal……结束了啊……
今年最后一场比赛,忽然感觉,上大真的太好。
在其他的学校,我这种模板都没打全的弱鸡,别说出去打比赛,集训队都不一定呆的住吧。。
然而还是羞耻地出来打final了。
结果侥幸炼铜
我自己感觉的话,其实还是。。我这个学习习惯。。没救了。。
看了下时间,现在是2016年12月14日01:41:28
我居然还在实验室瞎搞……
占坑,先学习一下markdown怎么写。
一行上打印连续k个单词的花费为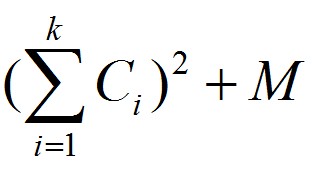 ,
,
给你每个单词的花费 ,
求最后总的最小花费。
很容易想到的dp式是:
然而 直接这么做的话肯定是做不到 的。
于是把上面的式子变形一下,首先斜率优化是针对决策过程而不是dp的,所以关注 这个决策。
$$
dp[j] + (\sum_{h=j+1}^iC_h)^2 +M< dp[k] + (\sum_{h=k+1}^iC_h)^2+M
$$
其中 $\sum_{h=j+1}^iC_h$可以用前缀和来表示。
拆开变形,
令
也就是说
那么从左到右,对 ,如果
此时如果在 点做决策。
所以j点可以直接排除。
也就是说,对于做过优化的点集,要求
恒成立。对于一般的映射g,要维护这个性质需要 的复杂度。但是这里很多时候可以用斜率优化。。
令 ,这里 满足单调性,因此可以把 离散化。
那 满足
也就是对 ,后面的斜率比前面的斜率大,保持下凸性。

如上图。
这里维护点集的方法和求凸包时使用的方法一样,维护一个队列(栈),对每一个新加入的点,出栈直到
最后满足
求解的时候,
此时,
就是最优决策!